

大數(shù)據(jù)時代下生命科學研究面臨的挑戰(zhàn)及解決方案
2024-06-27 10:09
來源:中國網·中國發(fā)展門戶網




中國網/中國發(fā)展門戶網訊 在過去的幾個世紀中,生命科學一直處于快速發(fā)展和演變的階段,從最初對生命現(xiàn)象的簡單觀察和描述,到如今分子生物學、基因組學和系統(tǒng)生物學等領域的興起,生命科學研究范式持續(xù)演變。這種研究范式的變化深受生物數(shù)據(jù)類型和規(guī)模的發(fā)展所推動,并帶來了生命科學發(fā)展演進的3個階段(圖1)——每個階段都在前一個階段的基礎上遞進,不斷涌現(xiàn)新的技術和方法來快速推動生命科學研究的不斷進步。
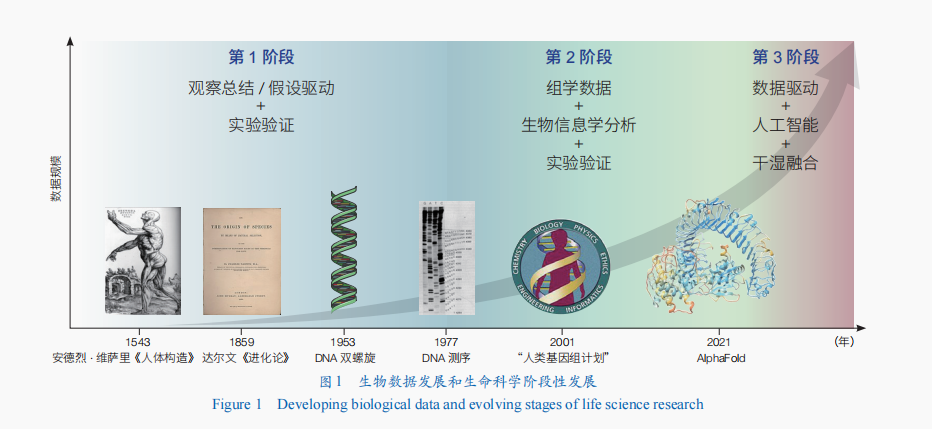
第1階段(16世紀—20世紀下半葉):以觀察總結和假設驅動為主,實驗數(shù)據(jù)作為輔助支持和驗證依據(jù)。在早期,生物學家主要依靠手工實驗和觀察描述獲取數(shù)據(jù),并從中提煉歸納出一些假說。但這些數(shù)據(jù)通常是表面的、局部的、有限的,產生的假說也是宏觀和粗略的,無法對生命的深層機制進行解析。其原因在于認知水平和技術的限制導致無法獲得和解析更深層次的生物學數(shù)據(jù)。這一時期的生命科學研究的典型代表有:16世紀的安德烈·維薩里通過動物和人體的解剖數(shù)據(jù)全面認識機體結構;19世紀,達爾文通過環(huán)球考察采集和分析大量標本數(shù)據(jù)提出進化論等。其后,隨著物理學、化學等學科的發(fā)展,以及實驗技術和分析方法的快速進步,尤其是DNA雙螺旋結構的發(fā)現(xiàn)和中心法則的提出,將生命科學研究引入分子生物學時代。生物學家可以將復雜的生命系統(tǒng)拆解為微觀的分子和細胞組分并逐個進行研究,以獲得對生物系統(tǒng)單一維度、深層次的描述數(shù)據(jù)。研究人員通常采用被動分析的方法,即根據(jù)事先提出的假設來遍歷和解釋實驗數(shù)據(jù),此時形成的是對生命系統(tǒng)深入卻零散、片面的認知。
第2階段(20世紀下半葉—21世紀初):以組學數(shù)據(jù)為基礎,結合生物信息學分析和實驗驗證。測序技術的出現(xiàn)和“人類基因組計劃”的實施將生命科學引入了高通量生物研究時代。基因組學、轉錄組學、表觀組學、糖組學等多種組學技術呈現(xiàn)了細胞在不同層面的整體生命圖景。生物學家能夠在早期發(fā)育、癌癥、衰老、疾病等多個生命過程中進行高通量、大規(guī)模的數(shù)據(jù)采集。此時,他們不再局限于驗證特定的假設,而是通過多種組學數(shù)據(jù)來探索未知領域。多組學數(shù)據(jù)的分析需要更復雜的計算工具和算法,包括生物信息學、統(tǒng)計學等。這些工具和方法幫助研究人員從海量數(shù)據(jù)中發(fā)現(xiàn)隱藏的模式和關聯(lián),從而獲得更全面、更深入的生物學知識。另外,使用生物信息學對組學數(shù)據(jù)分析獲得的知識還需要使用濕實驗進行驗證。盡管這一階段能夠對生物學數(shù)據(jù)進行低維度的描述和解釋,卻難以對復雜的生命系統(tǒng)進行高維度模擬,以實現(xiàn)對生命的全面系統(tǒng)解析。
第3階段(21世紀初至今):以生物大數(shù)據(jù)驅動,使用人工智能和干濕融合對生命系統(tǒng)進行解析與重構。生命系統(tǒng)呈現(xiàn)分子、細胞、組織、個體等多層次的結構,并且這些層次之間高度互聯(lián)、動態(tài)調控,形成了一個復雜的系統(tǒng);而由此獲得的數(shù)據(jù)也具有多層次、動態(tài)變化的特點。此外,隨著生命科學研究的不斷深入,海量的多組學數(shù)據(jù)、文獻資料和其他生物學數(shù)據(jù)持續(xù)涌現(xiàn)和積累,從而導致數(shù)據(jù)規(guī)模和復雜性進一步增加。這種多類型、多維度且體量巨大的生物學數(shù)據(jù)被稱為生物大數(shù)據(jù)。然而,傳統(tǒng)的數(shù)據(jù)分析方法已經無法滿足處理這一復雜性的需求。針對不同層次、不同維度、不同類型的生物大數(shù)據(jù)進行有效整合、匯集和深入分析,以揭示其中蘊含的高維度生物規(guī)律,成為當今生命科學研究面臨的挑戰(zhàn)之一。人工智能,尤其是神經網絡技術,因其擅長從低維度的大規(guī)模數(shù)據(jù)中提取高維度隱匿規(guī)律的優(yōu)勢成為解決這一挑戰(zhàn)的有效工具。例如,AlphaFold能夠預測蛋白質的三維結構,GeneCompass等工具能模擬基因調控網絡。這些工具和技術證明了使用人工智能可以挖掘生物大數(shù)據(jù)中數(shù)據(jù)之間的關聯(lián),抽提生命的內在結構,從而更全面地理解生命現(xiàn)象的本質和規(guī)律,揭示生物體內部復雜的互動關系和調控機制。然而,當前人工智能技術仍然僅能有效整合、分析某一層面的生物數(shù)據(jù)(如轉錄組)。要實現(xiàn)對復雜互聯(lián)的生命系統(tǒng)進行全面、系統(tǒng)和深刻的認知,需要積累更多的系統(tǒng)性生物大數(shù)據(jù),并運用人工智能技術對多模態(tài)的生物大數(shù)據(jù)進行有效整合,以實現(xiàn)對生命系統(tǒng)整體圖景的認知。而且,人工智能指導的自動化機器人已經實現(xiàn)了在化學和材料學上自主設計、規(guī)劃和執(zhí)行真實世界的實驗,從而顯著提高了科學發(fā)現(xiàn)的速度和數(shù)量,并改善了實驗結果的可復制性和可靠性。未來使用生物大數(shù)據(jù)訓練的人工智能結合自動化機器人,將可能建立干濕融合的自進化研究新范式,以實現(xiàn)對更復雜的生命系統(tǒng)進行更高效和更深入的解析。
綜上,生物學數(shù)據(jù)推動生命科學發(fā)展經歷了從觀察總結和假設驅動為主、組學數(shù)據(jù)為基礎到生物大數(shù)據(jù)驅動的3個遞進階段。在這個過程中,生物學數(shù)據(jù)呈現(xiàn)規(guī)模遞增、類型豐富和層次加深的特點,也推動了對生命本質的認知從對生命系統(tǒng)宏觀總結、生命元件深入認知、生命系統(tǒng)全面低維度描述到生命系統(tǒng)解析和重構的不斷深入。
數(shù)據(jù)驅動生命科學研究的內涵和特點
數(shù)據(jù)驅動生命科學研究的內涵體現(xiàn)在其對研究范式、方法論和認知模式的深刻影響上。強調了以數(shù)據(jù)為核心的研究方法,將數(shù)據(jù)的采集和分析置于中心位置。這意味著研究者不再僅依賴于個別案例或局部現(xiàn)象,而是通過收集大規(guī)模、多樣化的生物學數(shù)據(jù)來推動研究的發(fā)展。數(shù)據(jù)驅動的生命科學研究具有跨學科性和整合性的特點。隨著技術的發(fā)展和數(shù)據(jù)的積累,生命科學的研究越來越需要跨越不同學科領域,如生物學、計算機科學、統(tǒng)計學等,進行數(shù)據(jù)的整合和分析。數(shù)據(jù)驅動的生命科學研究著重于量化生物現(xiàn)象,并試圖將其系統(tǒng)化地理解。傳統(tǒng)的生物學研究往往是基于定性觀察和描述,而數(shù)據(jù)驅動的方法則更加注重通過數(shù)據(jù)收集、處理和分析,建立生物系統(tǒng)的量化模型。這種量化和系統(tǒng)化的方法使得研究者能夠更全面地理解生命系統(tǒng)的復雜性,并從中發(fā)現(xiàn)隱藏的規(guī)律和關聯(lián)。數(shù)據(jù)驅動的生命科學研究強調實驗數(shù)據(jù)與數(shù)字化建模的結合。通過收集大量的實驗數(shù)據(jù),并運用數(shù)學模型和計算方法進行數(shù)字化建模,進行高通量、高準確度地預測和篩選,從而可以高效驗證和修正生物學理論,并提出新的假設和預測。這種濕實驗與數(shù)字化建模結合的研究方式使得生命科學研究更加系統(tǒng)和深入,推動了生物學知識的不斷進步。
數(shù)據(jù)驅動生命科學研究的特征具有3項顯著性特點。生物學數(shù)據(jù)具有多樣性和豐富性的特點。生物數(shù)據(jù)涵蓋了生物系統(tǒng)的各個層次和多個方面——從基因組序列到蛋白質結構,再到細胞功能和生物表型,生物學數(shù)據(jù)包含了豐富的信息,為研究者提供了深入探索生命現(xiàn)象的基礎。生物學數(shù)據(jù)具有高維度和大規(guī)模的特點。隨著技術的進步,生物學數(shù)據(jù)的維度和規(guī)模不斷增加。例如,基因組學和轉錄組學等高通量測序技術的出現(xiàn),使得研究者能夠同時研究成千上萬個基因或基因表達物,從而獲得高維度的數(shù)據(jù)。這種高維度和大規(guī)模的數(shù)據(jù)為研究者提供了更全面的視角,使他們能夠發(fā)現(xiàn)更復雜的生物學規(guī)律。生物學數(shù)據(jù)往往具有動態(tài)性和時空特征。生物系統(tǒng)具有在不同時間和空間尺度上的變化。例如,轉錄組數(shù)據(jù)可以反映基因在不同發(fā)育階段或不同環(huán)境條件下的表達變化,蛋白質互作網絡數(shù)據(jù)可以揭示細胞內信號傳導的動態(tài)過程。這種動態(tài)性和時空特征使得研究者能夠更深入地理解生命系統(tǒng)的復雜性,并探索其調控機制和功能。
生物大數(shù)據(jù)組成和特點
大數(shù)據(jù)(Big Data)通常代表了大量、多樣、不斷變化且快速聚合屬性的巨型數(shù)據(jù)集,并且這些屬性過于復雜或“大”,無法通過傳統(tǒng)手段處理。而生物大數(shù)據(jù)在廣義上被定義為來源于或用于生物的海量數(shù)據(jù)。目前,比較常見的生物大數(shù)據(jù)類型包括:研究類型數(shù)據(jù),如基因組、蛋白質組、轉錄組、糖組等多種組學測序數(shù)據(jù),以及成像數(shù)據(jù)、藥物研發(fā)和臨床試驗數(shù)據(jù)等;電子健康數(shù)據(jù),如電子醫(yī)療檔案、可移動/穿戴設備采集的實時監(jiān)控數(shù)據(jù)等;生物樣本庫,如生物多樣性資源庫、臨床樣本庫等;知識成果,如生物相關的文獻、專利、標準等。
生物大數(shù)據(jù)除了具備“大數(shù)據(jù)”的特點外,還具有明顯的生物學數(shù)據(jù)自身特性,即大數(shù)據(jù)量(volume)、多樣化(variety)、高速(velocity)和有價值(value)的“4V”特點(圖2)。生物學研究技術和手段的快速發(fā)展推動了生物大數(shù)據(jù)的高速發(fā)展,使生物學研究從表面的點觀測進入全面和更深層次的圖像和數(shù)據(jù)解析。
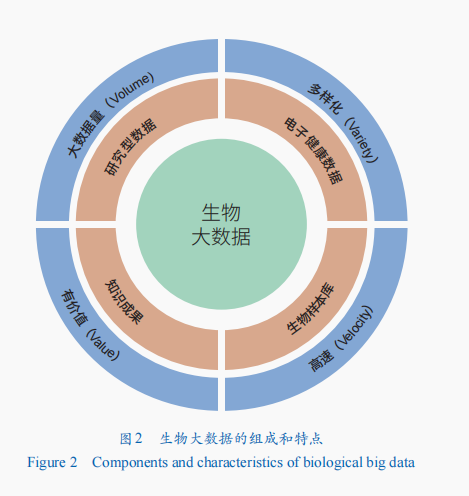
大數(shù)據(jù)量。容量是大數(shù)據(jù)中涉及的數(shù)據(jù)量的絕對大小。國際癌癥組織建立了癌癥基因組圖譜計劃(TCGA),目前已收錄的來自各種癌癥的組學數(shù)據(jù)已突破2.5 PB。自2015年,中國科學院北京基因組研究所(國家生物信息中心)建立了國內首個組學原始數(shù)據(jù)匯交、存儲、管理與共享系統(tǒng)GSA(組學原始數(shù)據(jù)歸檔庫),目前數(shù)據(jù)量已突破42 PB。數(shù)據(jù)庫的數(shù)據(jù)量上升速度之快完美地凸顯了生物大數(shù)據(jù)的蓬勃發(fā)展。
多樣化。多樣化代表所收集數(shù)據(jù)的多樣性,組學技術的進步和電子醫(yī)療的出現(xiàn),產生了不同來源、不同格式和不同用途的大量數(shù)據(jù),擴大了可用和需要處理的數(shù)據(jù)類型和數(shù)據(jù)源的范圍。對于生物學樣本的研究,經歷了從文本數(shù)據(jù)、圖像數(shù)據(jù)、芯片數(shù)據(jù)到高通量測序數(shù)據(jù)的變化,擴充了生物學的研究材料。
高速。速度是由輸入和處理數(shù)據(jù)的速度定義的,指的是數(shù)據(jù)創(chuàng)建、處理和分析的速度和頻率。近年來,為應對生物大數(shù)據(jù)的急劇增長,人工智能方法被用于生物大數(shù)據(jù)的解析。
有價值。價值表示所收集的數(shù)據(jù)在臨床研究的結果變化、行為改變和工作流程改進方面的有用性。所有研究性生物大數(shù)據(jù)的產出,都在特定的方面加深了生物學的認識,推動了生物學研究的發(fā)展,體現(xiàn)了生物大數(shù)據(jù)不可忽視的價值性。例如,臨床的影像學數(shù)據(jù)高效、精準地幫助醫(yī)生判斷患者的病灶和原因,測序數(shù)據(jù)的解析全面地闡釋了表型的根本原因等。
技術發(fā)展推動生物大數(shù)據(jù)的產生
生物技術和信息技術的融合推動了生命科學從“假說驅動”向“數(shù)據(jù)驅動”的轉變,促進了生物大數(shù)據(jù)的爆發(fā)式增長、精準解析和生命科學的巨大進步。自從“人類基因組計劃”實施以來,測序技術得到了快速發(fā)展,引發(fā)了基因組、轉錄組、表觀遺傳組、蛋白質組、代謝組、糖組等多種組學數(shù)據(jù)急劇增加,同時也催生了生物技術與信息技術的融合,推動生命科學研究進入數(shù)據(jù)型科學發(fā)現(xiàn)的時代。
在生命科學的發(fā)展過程中,得益于測序技術的快速發(fā)展,組學類型的生物大數(shù)據(jù)增長尤為凸顯。自1977年Sanger第一代測序技術出現(xiàn)以來,第二代高通量測序技術、第三代單分子全長測序技術和第四代納米孔測序技術相繼涌現(xiàn),廣泛應用于生物學各個領域,推動了生命科學研究的巨大進步。Sanger測序技術被用于細菌和噬菌體基因組的測序,但其1次只能分析1個測序反應,產量有限、時間花費長且成本高昂,導致“人類基因組計劃”耗時10多年才完成。自2004年以來,“下一代測序”(next-generation sequencing)技術的發(fā)展實現(xiàn)了高通量平行測序,大幅增加了測序數(shù)據(jù)的輸出量。第二代測序技術支持基因組、轉錄組和表觀遺傳組等多種組學測序,單次測序可以產生4億條讀段、120 GB數(shù)據(jù)。第三代測序技術又被稱為“長讀段”測序,可以檢測全基因組重復和結構變異檢測,實時靶向讀取DNA分子。最新的第三代測序儀,平均讀長可達10—15 kb,產生約36.5萬個讀段。第四代測序技術是基于納米孔系統(tǒng)的DNA測序技術,裝置小巧可達手持尺寸,超過100 kb的DNA可以穿過納米孔,通過許多通道,以相對較低的成本獲得數(shù)十到數(shù)百Gb的序列。測序技術的快速發(fā)展對基礎研究、臨床診斷治療等具有重要意義。隨著精準醫(yī)療概念的提出,電子健康記錄開始發(fā)展。盡管存在不適當訪問等潛在風險,但電子健康記錄的便攜性、準確性和即時性為精準醫(yī)療策略、醫(yī)療體系完善和智能療法篩選等提供了重要支持。
在生命科學研究中,信息技術和生物技術的規(guī)模化應用豐富了生物樣本庫的建設。伴隨著生物大數(shù)據(jù)的急劇增長,美國國立生物技術信息中心(NCBI)數(shù)據(jù)庫、歐洲生物信息學研究所(EBI)數(shù)據(jù)庫、日本DNA數(shù)據(jù)庫(DDBJ)和中國國家基因組數(shù)據(jù)中心等大數(shù)據(jù)庫中的數(shù)據(jù)類型不斷豐富,包括從多組學測序原始數(shù)據(jù)到表達信息矩陣,數(shù)據(jù)量從TB向PB甚至更高不斷增加,從而為生命科學領域的研究提供了豐富的數(shù)據(jù)資源。此外,生物大數(shù)據(jù)的發(fā)展也推動了知識成果的積累,促進了生物學數(shù)據(jù)相關文獻不斷提升和生物技術專利的快速更新迭代,極大地推動了生物領域的研究,有望給生物學和生物醫(yī)學研究領域帶來革命性的變化。
大數(shù)據(jù)時代下生命科學研究面臨的挑戰(zhàn)及解決方案
面對生物大數(shù)據(jù)驅動生命科學研究新范式的發(fā)展趨勢,研究人員面臨著來自不同來源的多維度大數(shù)據(jù)的挑戰(zhàn)。這些大數(shù)據(jù)包括龐大的結構化和非結構化的信息集合。如何有效地從如此龐大的原始數(shù)據(jù)中提取信息對于推動科學發(fā)明、工業(yè)進步和經濟發(fā)展至關重要。隨著新型生物技術的發(fā)展,具有多模態(tài)、多維度、分布分散、關聯(lián)隱匿、多層次交匯等特點的生物大數(shù)據(jù)逐漸形成。如何建立適合生命科學的數(shù)據(jù)處理和分析流程,構建共享可及且高速傳輸?shù)臄?shù)據(jù)庫,有效整合數(shù)據(jù),為生命科學AI Ready(人工智能就緒)的實現(xiàn)提供完整、安全、真實和契合的高質量數(shù)據(jù),將促進新的科學發(fā)現(xiàn)并拓展生命科學的探索范圍。
生物大數(shù)據(jù)處理的挑戰(zhàn)
大量的數(shù)據(jù)在收集整合過程中,因不同實驗室和研究人員之間的差異及技術平臺差異等因素都可能引起批次效應。批次效應會導致數(shù)據(jù)變異性增加,真陽性生物信號和假陰性信號的膨脹。當批次效應被誤認為感興趣的結果(假陽性)時,可能會引發(fā)更嚴重的后果。針對批次效應,如今較為公認的方法包括:ComBat包,通過經驗貝葉斯估計器來校正數(shù)據(jù)的批次效應;Seurat包,通過建立錨定的方法將不同批次之間相似的細胞集成單細胞簇。
除了批次效應的存在,數(shù)據(jù)也可能出現(xiàn)缺失的情況,會導致建模偏差增加或模型準確性降低的問題。針對不同的缺失情況,有著不同的插補解決方案。最簡單的插補方法是將信息替換為數(shù)據(jù)全局特征的值(平均值或中位數(shù)等),但是簡單的插補會導致標準誤差太小,未考慮不確定性。多重插補方法是處理缺失值最常用的方法,即多次對缺失值進行插補,并結合結果以考慮觀察到的變異性并減少推斷誤差。
大量生物學數(shù)據(jù)的出現(xiàn),不可避免地會出現(xiàn)批次效應和缺失。針對這些問題優(yōu)化統(tǒng)一前期數(shù)據(jù)處理的流程,并開發(fā)更加合理的處理批次效應和插補缺失值的方法,以使分析結果更加的可靠,避免出現(xiàn)假陽性的結果。但這些方法只能限制批次效應和減少數(shù)據(jù)缺失的影響,最終仍需要制定統(tǒng)一的實驗和數(shù)據(jù)標準。
生物大數(shù)據(jù)分析的挑戰(zhàn)
大數(shù)據(jù)的出現(xiàn)不僅為深入研究生物系統(tǒng)提供了前所未有的機會,也為數(shù)據(jù)挖掘和分析提出了新的挑戰(zhàn)。大數(shù)據(jù)分析的首要需求是找到兼顧成本和時間的解決方案。建立有效的生物信息工作流程系統(tǒng)和分析工具對生物數(shù)據(jù)的分析至關重要。機器學習和深度學習已成為從生物大數(shù)據(jù)生成處理信息的最先進技術,這些技術在Cloud、Hadoop、apache Spark等大數(shù)據(jù)平臺上執(zhí)行時,可以有效地從此類生物大數(shù)據(jù)中提取信息。針對多組學數(shù)據(jù)異構化的性質,使用具有并行計算的分布式系統(tǒng)的算法適合大數(shù)據(jù)分析。如MapReduce可以在由數(shù)千臺計算機組成的大型集群上使用各種并行和分布式算法。
針對生命科學數(shù)據(jù)的高維度、異質性和復雜性等特征,應著力發(fā)展生物大數(shù)據(jù)的先進分析方法和工具,以加快大數(shù)據(jù)分析速度、減少分析成本、降低分析的技術壁壘。建立標準的大數(shù)據(jù)分析流程,以期能夠得到準確、可復現(xiàn)和可解釋的分析結果。數(shù)據(jù)驅動的研究新范式的發(fā)展對數(shù)據(jù)分析的方法、工具和算力等資源提出了新的挑戰(zhàn),需要加快建設新一代數(shù)據(jù)分析基礎建設,以做好迎接新范式的準備。
生物大數(shù)據(jù)共享可及的挑戰(zhàn)
在全國乃至全球范圍內,生物數(shù)據(jù)的共享可及是大數(shù)據(jù)研究的重要組成部分。需要建立數(shù)據(jù)庫用于儲存原始或分析結果數(shù)據(jù),以實現(xiàn)數(shù)據(jù)公開和可共享。國際上已經建立了多個用于儲存生命科學數(shù)據(jù)的數(shù)據(jù)庫。例如,NCBI建立的GenBank數(shù)據(jù)庫是世界上最大的基因組數(shù)據(jù)庫之一。另外,蛋白質數(shù)據(jù)銀行(PDB)是一個著名的大分子結構信息數(shù)據(jù)庫,儲存了包括蛋白質、核酸等多種生物大分子的信息。我國國家基因庫生命大數(shù)據(jù)平臺(CNGBdb)已歸檔了3721個研究項目,多組學數(shù)據(jù)量達6612 TB,支撐了全球近300個科研單位的科研數(shù)據(jù)匯交和共享。需要高效的程序以使數(shù)據(jù)能夠快速且完整的提供給研究人員。Fasq是一個高效的數(shù)據(jù)傳輸軟件,它能夠在30 s內傳輸24 GB的數(shù)據(jù)。然而,它需要大量的互聯(lián)網連接帶寬,數(shù)據(jù)傳輸?shù)某杀痉浅0嘿F。Smart HDFS(Hadoop分布式文件系統(tǒng))是一種異步多管道文件傳輸協(xié)議,它使用全局和局部優(yōu)化技術來選擇更高性能的數(shù)據(jù)節(jié)點,從而提升數(shù)據(jù)傳輸?shù)男阅堋?/p>
盡管我國已經建立起如國家基因庫生命大數(shù)據(jù)平臺等的大型數(shù)據(jù)庫,但其存儲仍存在著規(guī)范性不強、存儲量不高、數(shù)據(jù)格式不統(tǒng)一、數(shù)據(jù)可用性不足和存在大量的使用壁壘等問題。因此,我國生命科學領域需要更好地統(tǒng)籌協(xié)調和資源整合,加強科學數(shù)據(jù)資源的整合與共享,建立規(guī)范化的數(shù)據(jù)存儲流程,構建高存儲容量、低使用壁壘的數(shù)據(jù)庫,以滿足數(shù)據(jù)驅動下的新范式的需求。面對數(shù)據(jù)傳輸?shù)奶魬?zhàn),我國還應該加強數(shù)據(jù)供給模式的改革,提升數(shù)據(jù)傳輸?shù)挠布O施,設計和優(yōu)化傳輸程序,以提供更加快速的傳輸速度為重點,并建立相關協(xié)議對數(shù)據(jù)訪問進行管理,進而保護數(shù)據(jù)的真實性。
建立大數(shù)據(jù)+生命科學研究新范式
將生物大數(shù)據(jù)處理成AI Ready狀態(tài)對于數(shù)據(jù)驅動的生命科學研究至關重要。這一過程為人工智能系統(tǒng)的訓練和優(yōu)化提供了基礎,并為人工智能系統(tǒng)提供了豐富的信息資源,有助于提高其理解世界的能力,增強預測和決策的準確性,實現(xiàn)個性化服務和定制化產品,同時推動創(chuàng)新和發(fā)現(xiàn)。面對生命現(xiàn)象中復雜的非線性關系和難以預測的特征,大數(shù)據(jù)驅動下的人工智能技術展現(xiàn)出強大的能力,并已在生命科學領域的多個方面展現(xiàn)出顛覆性的應用潛力。例如,Geneformer在基于3000萬個單細胞轉錄組的大規(guī)模語料庫進行了預訓練,以實現(xiàn)上下文特異性預測;跨物種生命基礎大模型GeneCompass在超過1.2億個單細胞的訓練數(shù)據(jù)集上實現(xiàn)了對基因表達調控規(guī)律的全景式學習理解等多個生命科學問題的分析。
然而,在我國在實現(xiàn)AI Ready過程中,核心技術仍相對匱乏,需大力發(fā)展自主原創(chuàng)的算法、模型和工具等。針對生命科學的AI Ready過程中大數(shù)據(jù)的多模態(tài)和多維度等特征,急需發(fā)展針對性的先進計算與分析方法。未來應開發(fā)更加適合生物大數(shù)據(jù)分析的硬件、軟件和新計算介質,并在生命科學和人工智能技術的融合過程中,探索新的人工智能-生物交互模式。充分利用人工智能+生物大數(shù)據(jù),同時與濕實驗結合,將建立干濕融合的生命科學研究新范式。
總結和未來展望
數(shù)據(jù)驅動的生命科學作為生物科學領域的重要趨勢,正面臨著海量生物大數(shù)據(jù)的包括數(shù)據(jù)存儲、傳輸、處理和分析等多個方面的挑戰(zhàn)。然而,通過不斷開發(fā)新的技術和方法,尤其是人工智能技術的發(fā)展,能夠更高效地整合和分析生物大數(shù)據(jù),從而挖掘生物學內在規(guī)律,深入理解生物系統(tǒng)的復雜性。
未來,為實現(xiàn)對復雜生命系統(tǒng)更完美的模擬和解構,需從數(shù)據(jù)質量、處理算法、場景化等多方面進行優(yōu)化。應生產和獲取高質量系統(tǒng)性的生物大數(shù)據(jù)。當前的生物學數(shù)據(jù)雖然規(guī)模大、類型多,但數(shù)據(jù)來源各異、離散度高、偏差大,整體數(shù)據(jù)質量水平不高。而且生命系統(tǒng)是多層級的復雜系統(tǒng),要將不同層級打通,需要如胚胎發(fā)育、疾病、癌癥、衰老等生命過程的多維度、多模態(tài)、時空對齊的高質量、系統(tǒng)性生物大數(shù)據(jù),為人工智能提供可靠的數(shù)據(jù)基礎,減少噪聲和偏差的影響。需開發(fā)生命適配的人工智能算法。生物大數(shù)據(jù)具有多維度、多層次、非結構化和動態(tài)變化的特點,當前人工智能算法難以有效處理。未來需要針對生物數(shù)據(jù)特點開發(fā)生命適配的人工智能算法,來更好捕捉復雜生命網絡中的結構和規(guī)律。增強模型的解釋性,揭示潛在的生物學機制也是未來重要的研究方向。整合生物學數(shù)據(jù)、利用人工智能技術以及自動化的高通量實驗和數(shù)據(jù)獲取技術。有望實現(xiàn)干濕融合的自進化模式,為生命科學研究帶來革命性范式革新。
(作者:江海平、劉文豪、李鑫,中國科學院動物研究所 北京干細胞與再生醫(yī)學研究院;高純純、楊運桂,國家生物信息中心;編審:楊柳春。《中國科學院院刊》供稿)





